28. Data processing jobs with SageMaker
Data processing jobs with SageMaker
Prerequisites
1
S3
1. Connection with endpoint and Lambda
Data processing jobs are essential in modern machine learning pipelines because they separate data preparation from model training and inference.
In real-world scenarios, raw data is often large, inconsistent, and unstructured, making it inefficient or even impossible to process on the fly during training or prediction. By introducing a dedicated data processing stage, we can clean, normalize, transform, and organize data in advance, ensuring that both training and inference use the exact same data format.
This not only improves performance and reduces latency, but also eliminates inconsistencies that can degrade model accuracy. Additionally, processing jobs enable scalability by handling large datasets in distributed environments, and they support reusability by allowing preprocessed data to be stored and reused across multiple experiments.
In production systems, this separation is critical for building reliable, maintainable, and automated pipelines where each stage—data processing, training, and deployment—can evolve independently.
2. How to use Data processing jobs pane
1-1. Click Data processing jobs pane
1-2. Upload image_invert_processing.py and create job
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import io
import boto3
from PIL import Image
import numpy as np
s3 = boto3.client("s3")
INPUT_BUCKET = "amazon-sagemaker-xxxxxxx-ap-southeast-2-53c382f6781e"
INPUT_PREFIX = "raw/"
OUTPUT_PREFIX = "processed/"
response = s3.list_objects_v2(Bucket=INPUT_BUCKET, Prefix=INPUT_PREFIX)
for obj in response.get("Contents", []):
key = obj["Key"]
if not key.lower().endswith((".png", ".jpg", ".jpeg")):
continue
print("Processing:", key)
img_obj = s3.get_object(Bucket=INPUT_BUCKET, Key=key)
img_bytes = img_obj["Body"].read()
image = Image.open(io.BytesIO(img_bytes)).convert("L")
arr = np.array(image)
inverted = 255 - arr
new_img = Image.fromarray(inverted.astype(np.uint8))
buffer = io.BytesIO()
new_img.save(buffer, format="PNG")
buffer.seek(0)
output_key = key.replace(INPUT_PREFIX, OUTPUT_PREFIX)
s3.put_object(
Bucket=INPUT_BUCKET,
Key=output_key,
Body=buffer,
ContentType="image/png"
)
print("DONE")
1-3. Add Policy authorized with s3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::amazon-sagemaker-xxxxxx-ap-southeast-2-53c382f6781e",
"arn:aws:s3:::amazon-sagemaker-xxxxxx-ap-southeast-2-53c382f6781e/*"
]
}
]
}
1-4. Run the job
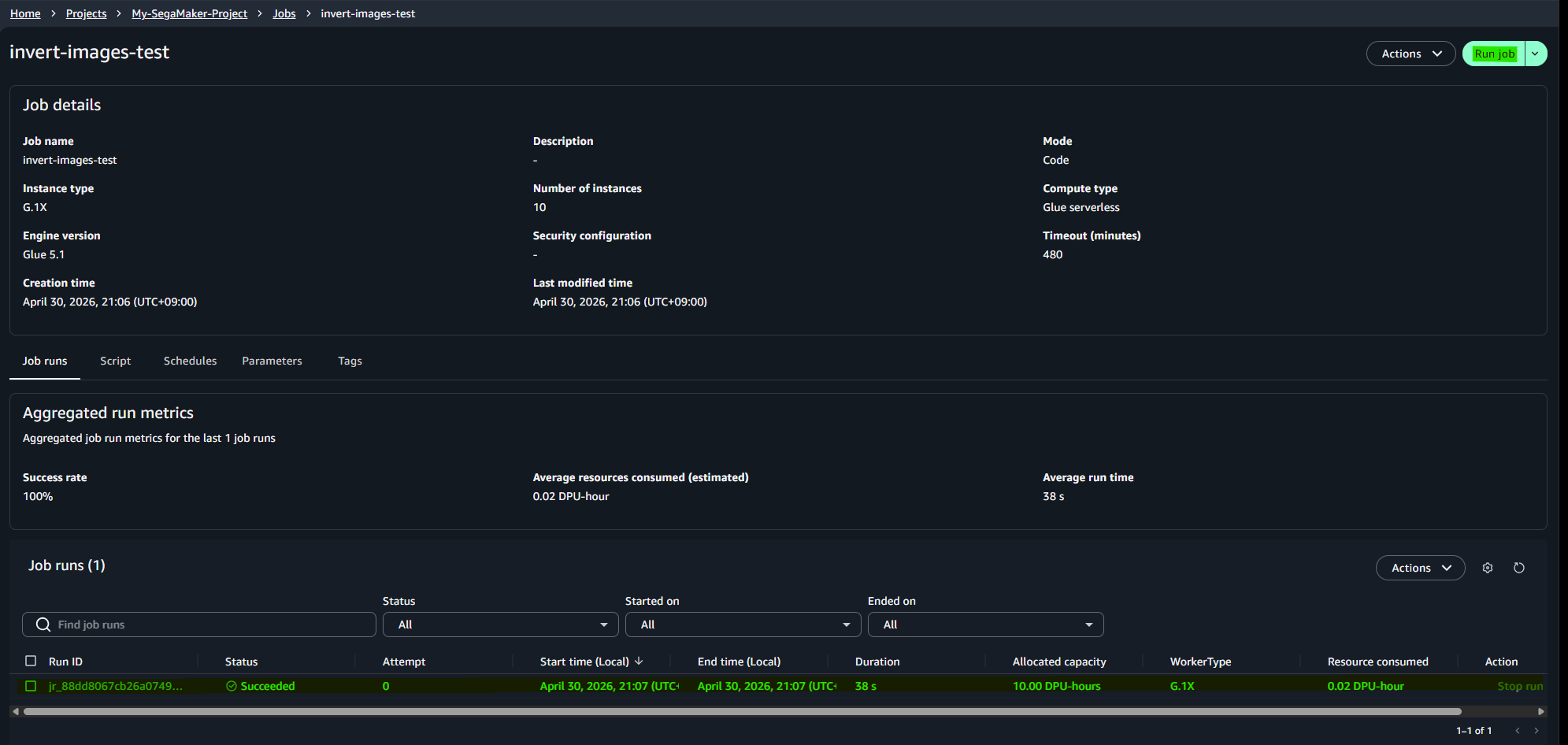
Result
