Hands-on 01. KMeans
Hands-on 01. KMeans
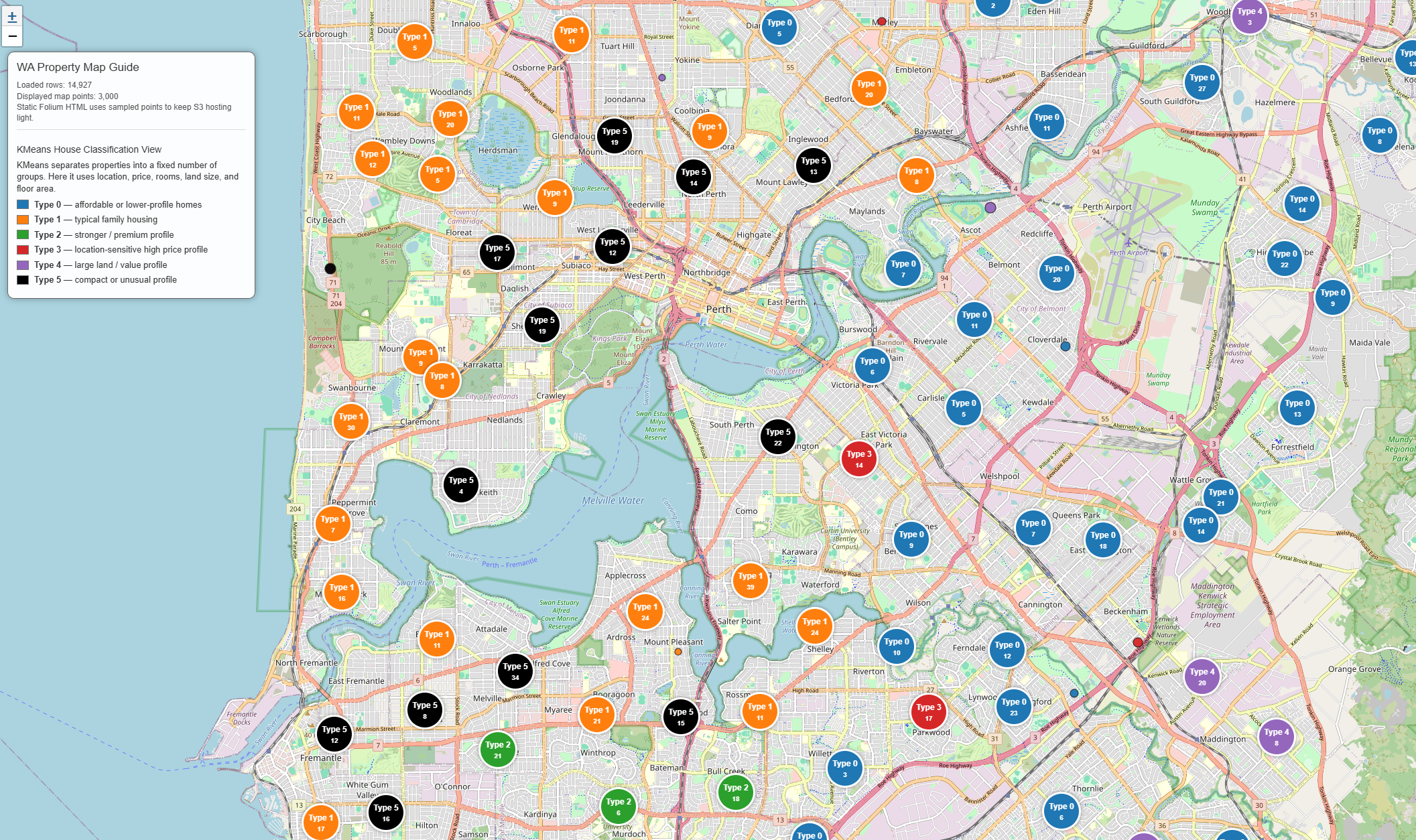
KMeans
Prerequisites
1
KMeans
1. How to implement the real
KMeans is kind of cluster. It should has parameters like variables you selected, count of clusters and numbers of implementation with another initialization.
Before we apply the tool, we have to control variable aspect to scale and so on. Because big number can overwhelm other features. So usually we transform the data with noralization.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import pandas as pd
from sklearn.cluster import MiniBatchKMeans
from sklearn.preprocessing import StandardScaler
RANDOM_STATE = 42
def add_kmeans_cluster(df, n_clusters=6):
features = [
"latitude", "longitude", "price",
"bedrooms", "bathrooms", "garage",
"land_area", "floor_area",
]
model_df = df.dropna(subset=features).copy() # Drop rows involved NA
# Condition check
if len(model_df) < n_clusters:
df = df.copy()
df["house_group"] = 0
return df
# scaling feature ~ N(0,1)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(model_df[features])
kmeans = MiniBatchKMeans(
n_clusters=n_clusters,
random_state=RANDOM_STATE,
batch_size=512,
n_init="auto",
)
model_df["house_group"] = kmeans.fit_predict(X_scaled)
df = df.copy()
df["house_group"] = 0
df.loc[model_df.index, "house_group"] = model_df["house_group"].astype(int)
return df
df = pd.read_csv("data.csv")
df = add_kmeans_cluster(df, n_clusters=6)
1-1. Data
- Select features you predicts effect the result
- Check whether the data is sufficient to calculate KMeans with the given number of clusters.
- Normalization for similar effect to result
1
2
[-31.95, 115.86, 750000, 4, 2, 2, 500, 180]
-> [-0.2, 0.5, 1.3, 0.7, -0.1, ...]
1-2. KMeans
- Select the number of clusters manually.
- Select method of init
- Process as follow:
- Initialize 6 centroids using k-means++.
- Sample a batch of 512 data points.
- For each data point, compute the distance to all 6 centroids.
- Assign each point to the nearest centroid.
- Update the centroids slightly based on this batch.
- Repeat with the next batch.
- Update Cluster information to data
This post is licensed under CC BY 4.0 by the author.