Hands-on 02. PCA
PCA
Prerequisites
1
PCA
1. How to implement the real
PCA transform the original diemension to reduced dimension that make high variance features. So there’s no interpretable elements when it comes to transformation. We just get the axis of new dimension and try to cluster with manual division or interpret by ourselves.
But sometimes we can interpret the new coordination on PCA dimension with tendency. It is absolutely subjective however it is useful.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
def add_pca_features(df):
features = [
"price", "bedrooms", "bathrooms", "garage",
"land_area", "floor_area", "latitude", "longitude",
]
model_df = df.dropna(subset=features).copy() # Drop rows involved NA
# create result space
df = df.copy()
df["pca1"] = np.nan
df["pca2"] = np.nan
df["pca_score"] = np.nan
if len(model_df) < 10:
return df, {"explained_variance": []}
# scaling feature ~ N(0,1)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(model_df[features])
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
model_df["pca1"] = X_pca[:, 0]
model_df["pca2"] = X_pca[:, 1]
model_df["pca_score"] = model_df["pca1"] + model_df["pca2"]
df.loc[model_df.index, ["pca1", "pca2", "pca_score"]] = model_df[["pca1", "pca2", "pca_score"]]
return df, {
"explained_variance": [float(v) for v in pca.explained_variance_ratio_],
"features": features,
}
df = pd.read_csv("data.csv")
df, pca_metrics = add_pca_features(df)
1-1. Data
- Select features you predicts effect the result
- Check whether the data is sufficient to calculate PCA with the given number of clusters.
- Normalization for similar effect to result
1
2
[-31.95, 115.86, 750000, 4, 2, 2, 500, 180]
-> [-0.2, 0.5, 1.3, 0.7, -0.1, ...]
1-2. PCA
- Select the size of dimension manually.
- Process as follow:
- calcuate covariance of features.
- calcuate eigenvalue and vector.
- select the eigenvalue starting from the largest and select that eigenvector
- dot product between eigenvector and normalized data
- Get new coordination
1.3 Try to interpret
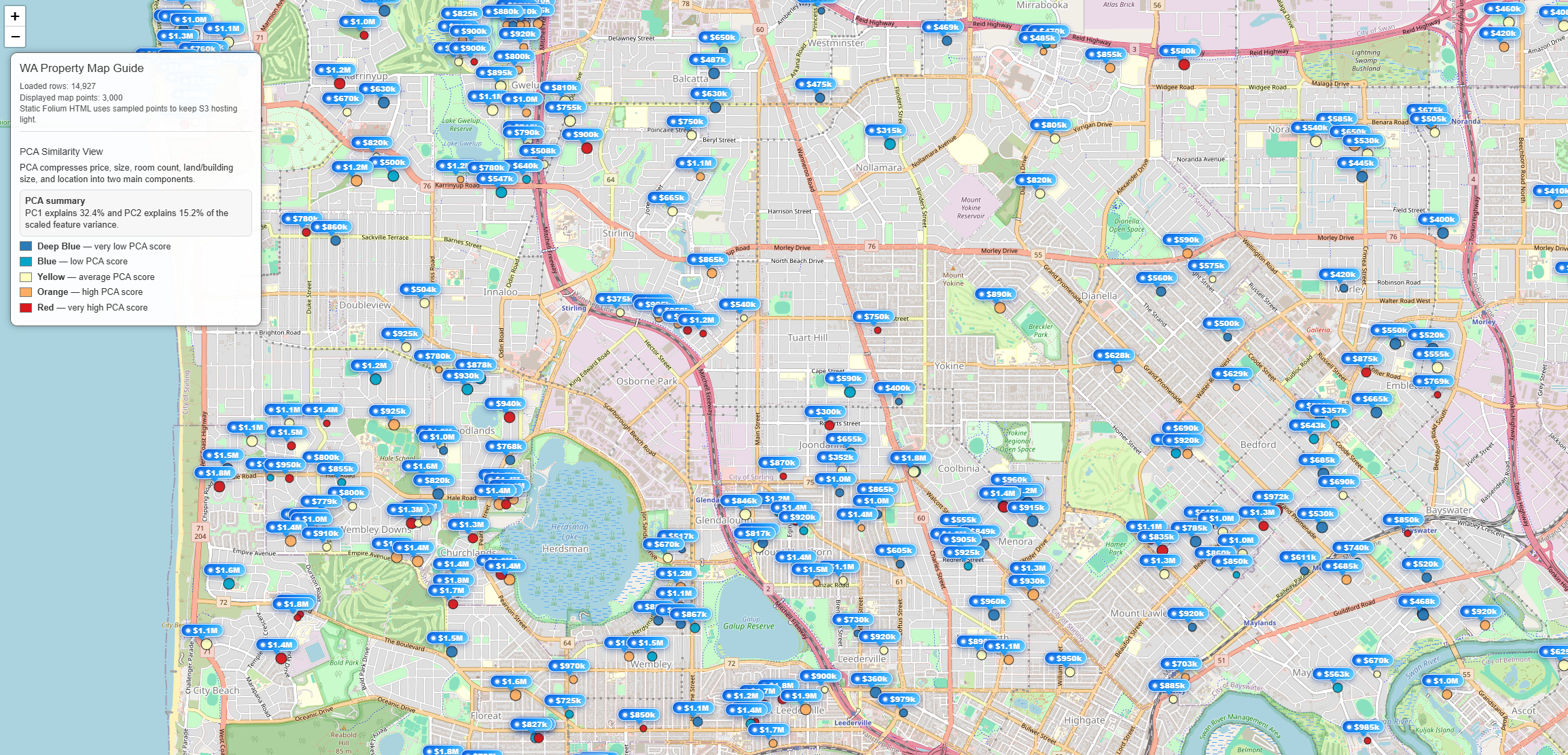
Above image, left side nearby offshore is more higher than right side. Maybe the features (price, bedrooms, bathrooms, garage, land_area, floor_area) are positive relationship that some variable is getting larger, the others are also larger in common.
So we can guess in this case, if the pca value is high meaning is expensive properties than low pca value properties.