01. Transformer Insight
Transformer Insights
Prerequisites
1
1. Transformer
Transformer structure should be understood by yourself
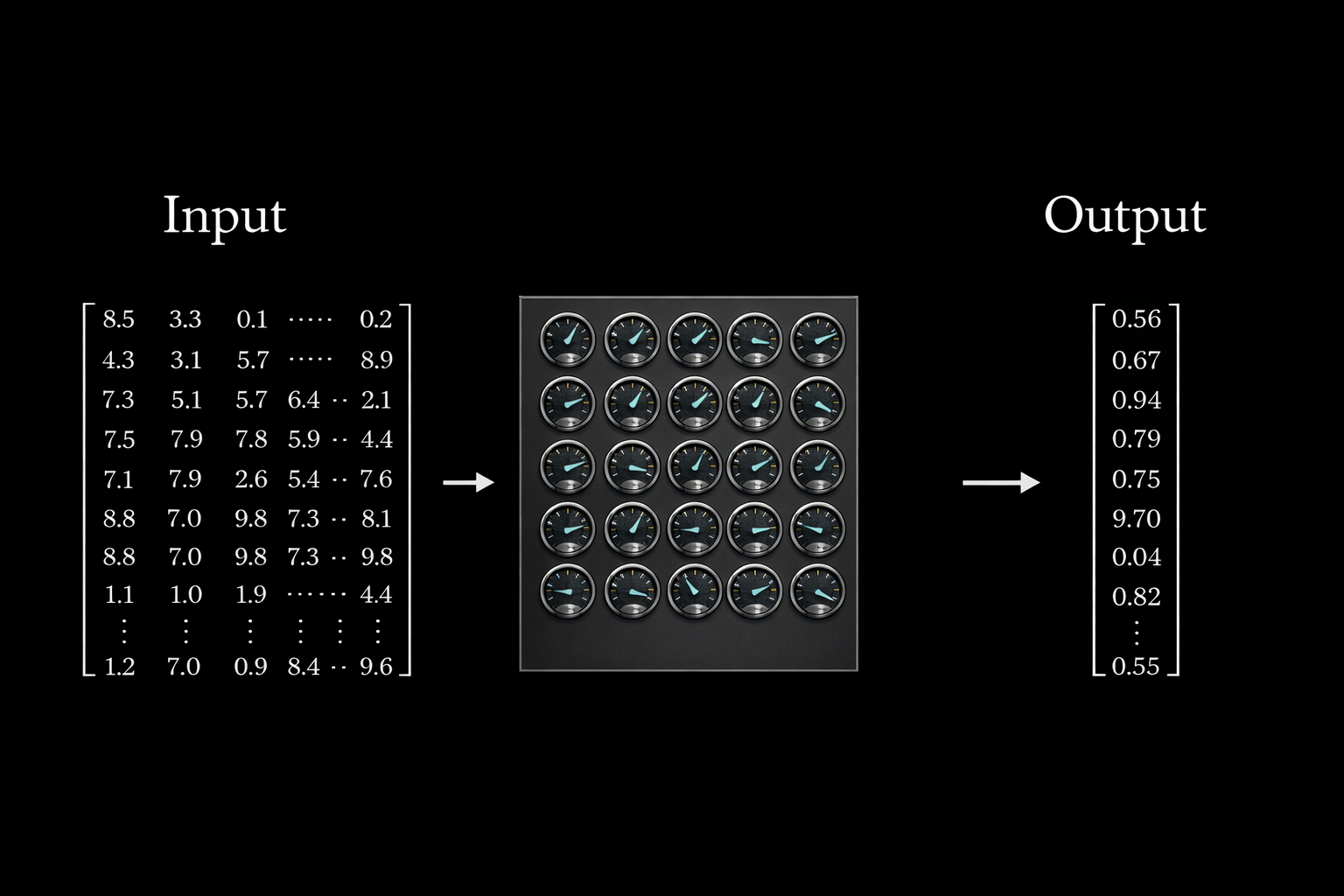
Transformer Process
1. Transformation Space to Query, Key, Value?
1
Space Transformation
There’re 3 main tricks of attention. Query, Key, Value.
Let’s think about transforming from input to query. For example, there’re the input dimension $ [Tokens: of: sentences] \times [embedding: size) $ and the query weight dimension $ [embdding: size] \times [query: size] $.
The times of between input and weight means that the process transform from input space(embedding size axis) to query space(query size axis). And the query weight is learnable or tunable space. So the space will be changed fit on task.
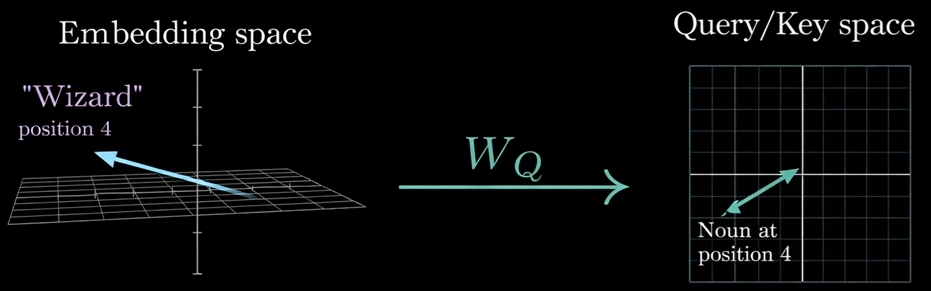
2. Attention Weight
1
2
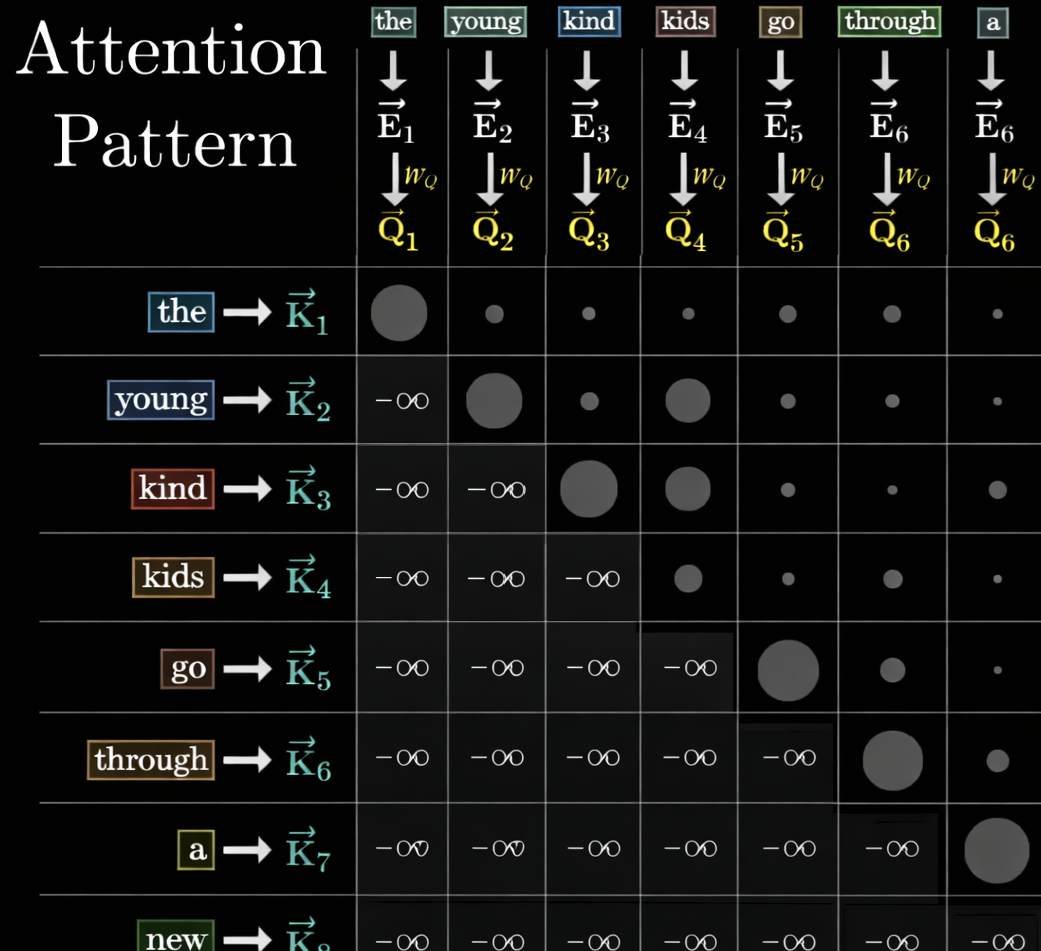
Attention weights
Relationship of Key Query
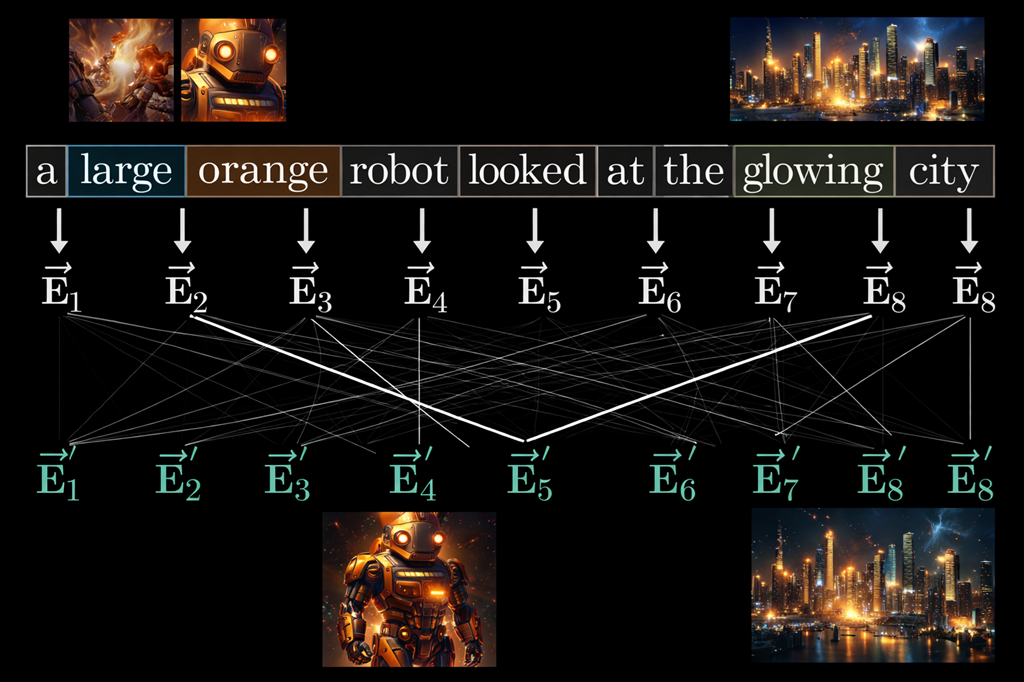
The Attention weight can make contextualization embedding. “A large orange robot” pharse is just 4 word embedding without attention weight. But with attention weight “Robot” can be more contextualized embedding.
The Attention weights are composed of key and query.
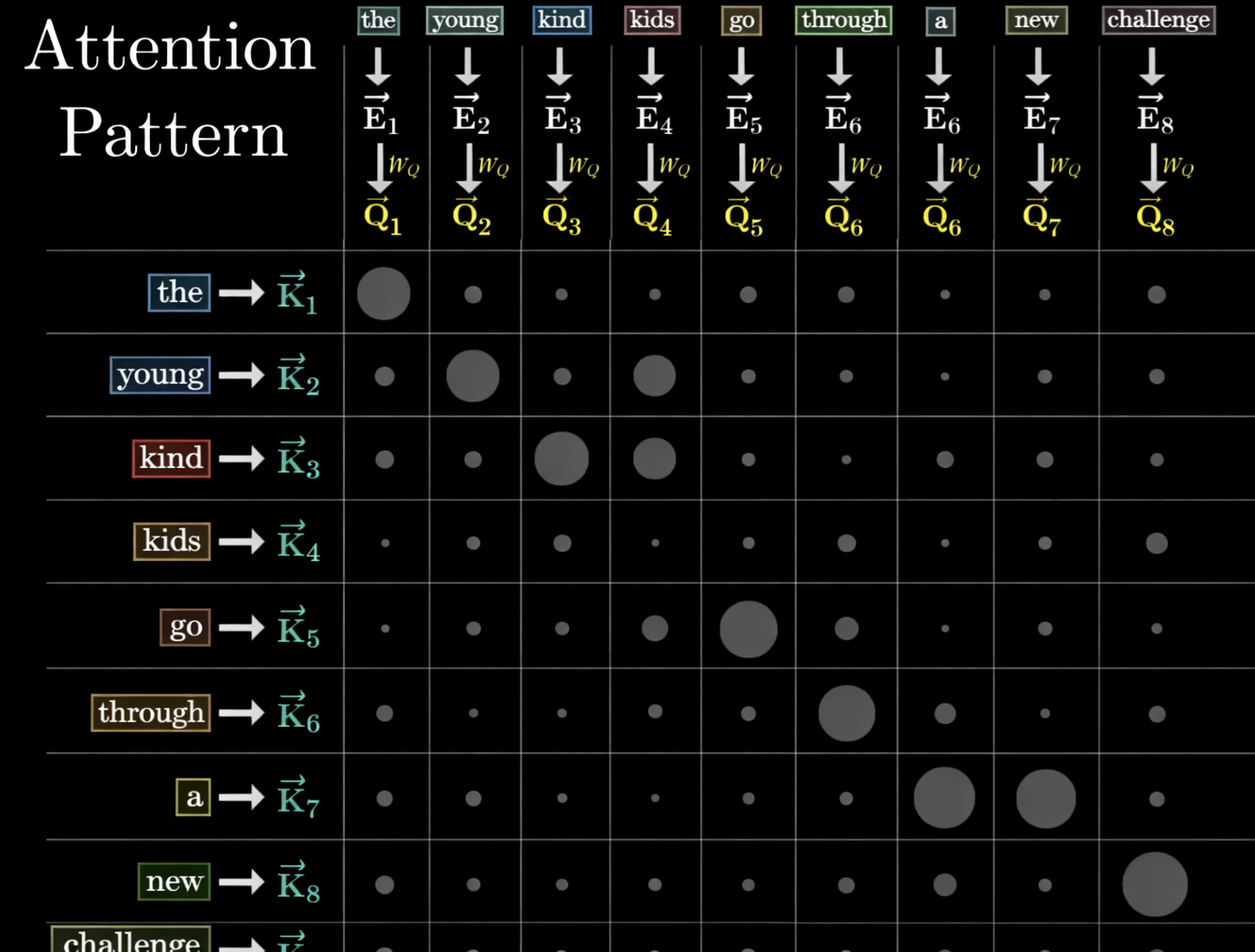
When we use maksed multi-head attention, we mask the lower triangular matrix. And think about the masked matrix times value weight. About query, just the previous and current key information are adapt to the value weight. That meaning is the mask will effect the value without future words.
3. Softmax with Temperature?
1
Temperature
Where:
- $T > 0$ is the temperature
- $T = 1$ → standard softmax
🔥 $T < 1$ (Sharper Distribution)
- Increases confidence
- Makes the highest probability closer to 1
- Approaches argmax behavior
❄ $T > 1$ (Softer Distribution)
- Flattens the probability distribution
- Increases uncertainty
- Encourages exploration
Numerical Example
Let:
\[z = [2, 1, 0]\]$T = 1$ :$ \approx [0.665, 0.245, 0.090] $
$T = 0.5$: $ \approx [0.867, 0.117, 0.016] $
$T = 2$: $ \approx [0.506, 0.307, 0.186] $
Intuition
Temperature scales the logits before exponentiation:
- Small $T$ → magnifies differences
- Large $T$ → compresses differences
It directly controls the entropy of the distribution.
4. Orthogonality and Information Capacity
Let the initial weight vectors be:
\[\mathbf{w}_i, \mathbf{w}_j \in \mathbb{R}^d\]Orthogonality condition:
\[\mathbf{w}_i^\top \mathbf{w}_j = 0 \quad (i \neq j)\]Information independence increases as:
\[\cos\theta_{ij} = \frac{\mathbf{w}_i^\top \mathbf{w}_j} {\|\mathbf{w}_i\|\|\mathbf{w}_j\|} \rightarrow 0\]Therefore, the information capacity is maximized when:
\[\mathbf{W}^\top \mathbf{W} = \mathbf{I}\]The more orthogonal the initial weight vectors are,
the greater the independent information capacity.
Mutual Information Perspective
Assume two representations:
\[h_i = \mathbf{w}_i^\top \mathbf{x}, \qquad h_j = \mathbf{w}_j^\top \mathbf{x}\]If the weight vectors are correlated:
\[\cos\theta_{ij} \neq 0\]then the outputs ( h_i ) and ( h_j ) are statistically dependent.
The mutual information between them is:
\[I(h_i ; h_j)\]When the vectors become more aligned, the mutual information increases due to shared directional components.
However, the total usable information in a representation layer is maximized when:
\[I(h_i ; h_j) = 0\]That is, when the features are statistically independent.
Orthogonality enforces zero linear correlation:
\[\mathbf{w}_i^\top \mathbf{w}_j = 0\]which reduces redundancy and maximizes effective representational capacity.
5. Dimension of Transformer?
EX. GPT-3
| Index | Dimension | Real | Percent |
|---|---|---|---|
| Emebdding | embedding x vocab | 12288 x 50257 | 0.353% |
| Key | key x embedding x heads x layers | 128 x 12288 x 96 x 96 | 8.274% |
| Query | query x embedding x heads x layers | 128 x 12288 x 96 x 96 | 8.274% |
| Value | value x embedding x heads x layers | 128 x 12288 x 96 x 96 | 8.274% |
| Output | embedding x value x heads x layers | 12288 x 128 x 96 x 96 | 8.274% |
| Up-projection | neurons x embedding x layers | 49152 x 12288 x 96 | 33.096% |
| Down-projection | neurons x embedding x layers | 49152 x 12288 x 96 | 33.096% |
| Unembedding | vocab x embedding | 50257 x 12288 | 0.353% |