10. 2D CNN Case Study
2D CNN Case Study
Models
1
2
3
4
5
1. AlexNet
2. ZFNet
3. VGGNet
4. GoogLeNet (Inception v1)
5. ResNet
AlexNet
1. Structure
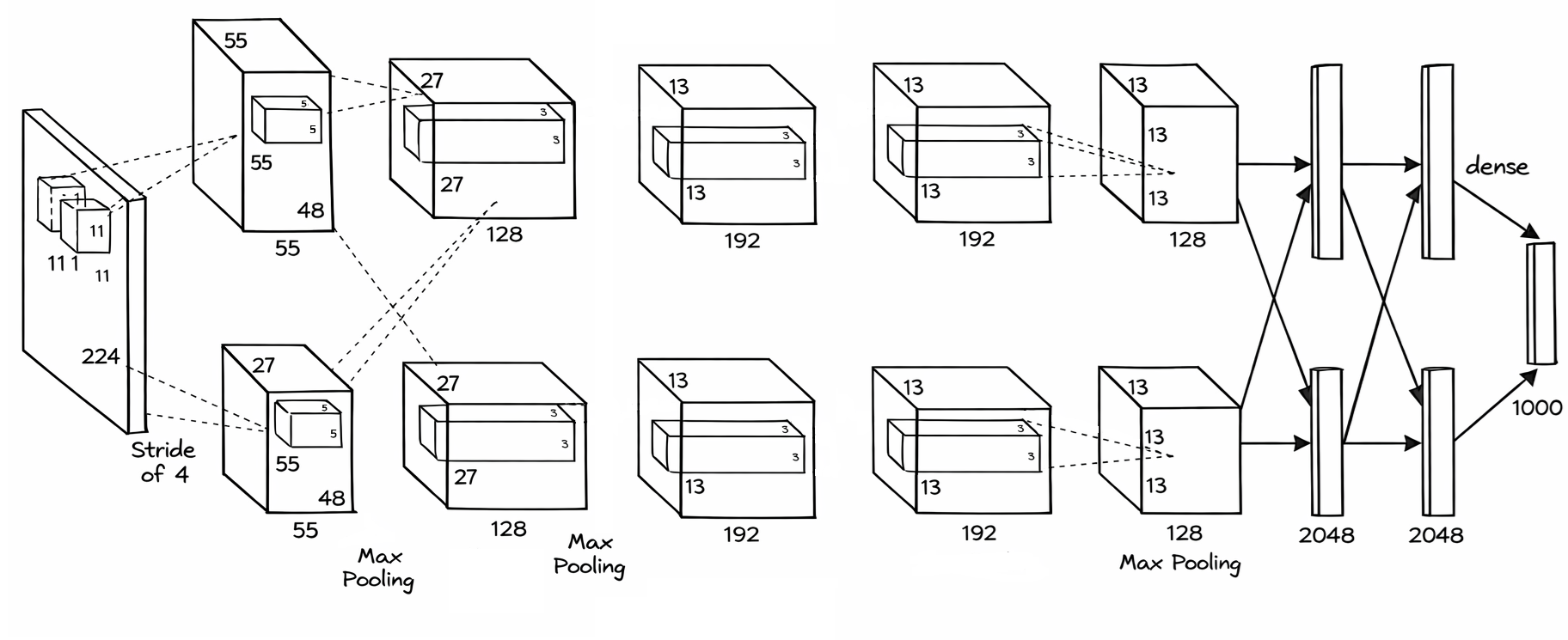
\begin{table}[h] \centering \begin{tabular}{llll} \hline Layer & Input & Filters & Output
\hline CONV1 & 224x224x3 & 96 filters 11x11, stride 4, pad 1.5 & 55x55x96
POOL1 & 55x55x96 & 3x3, stride 2 & 27x27x96
NORM1 & 27x27x96 & Normalization & 27x27x96
CONV2 & 27x27x96 & 256 filters 5x5, stride 1, pad 2 & 27x27x256
POOL2 & 27x27x256 & 3x3, stride 2 & 13x13x256
NORM2 & 13x13x256 & Normalization & 13x13x256
CONV3 & 13x13x256 & 384 filters 3x3, stride 1, pad 1 & 13x13x384
CONV4 & 13x13x384 & 384 filters 3x3, stride 1, pad 1 & 13x13x384
CONV5 & 13x13x384 & 256 filters 3x3, stride 1, pad 1 & 13x13x256
POOL3 & 13x13x256 & 3x3, stride 2 & 6x6x256
FC6 & 6x6x256 & Fully connected & 4096
FC7 & 4096 & Fully connected & 4096
FC8 & 4096 & Fully connected & 1000
\hline \end{tabular} \caption{AlexNet Architecture} \end{table}
2. Main Idea
- This model is innovative structure on that years. The main point of model is using non-linear activation, Dropout, parallel learning with GPU and Data Augmentation.
ZFNet
1. Structure
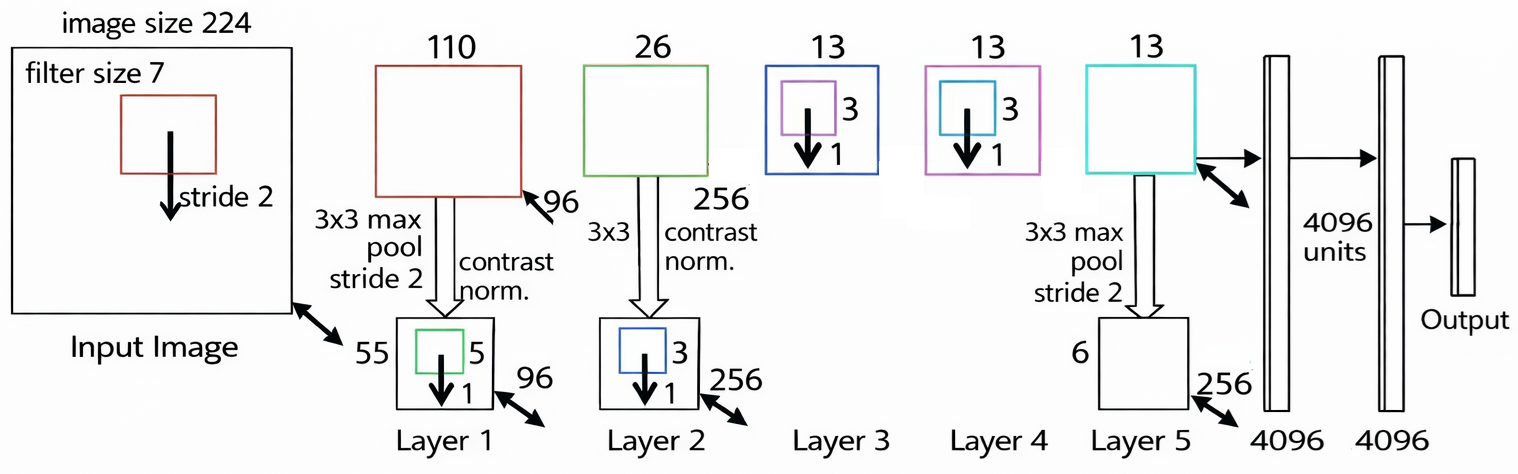
2. Main Idea
- This model is similiar to AlexNet. The main point of model found that large stride and kernel size is not efficient to performance.
VGGNet
1. Structure
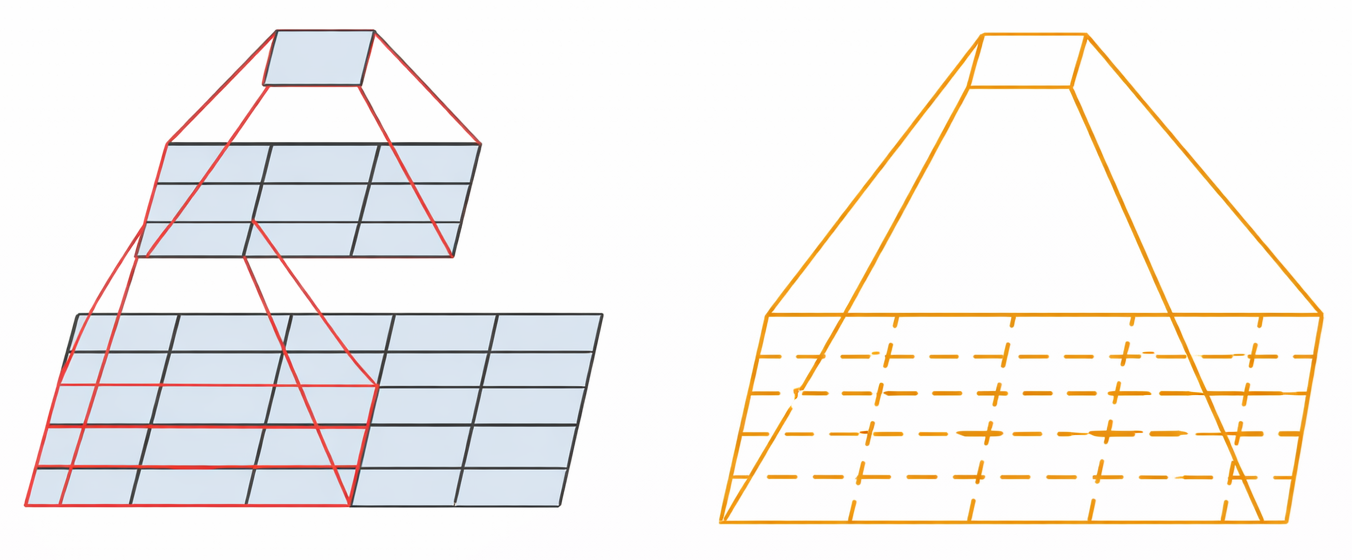
$No\; longer\; 11\; or\; 5\;size\; filters \rightarrow 3\;size\; conv\; filters\; only. $
2. Main Idea
- This model is similiar to AlexNet. The main point of model found that a number of 3x3 kernel size is more better than 5x5 or 11x11 kernel size because it is more efficient aspect to computational source.
GoogLeNet
1. Structure
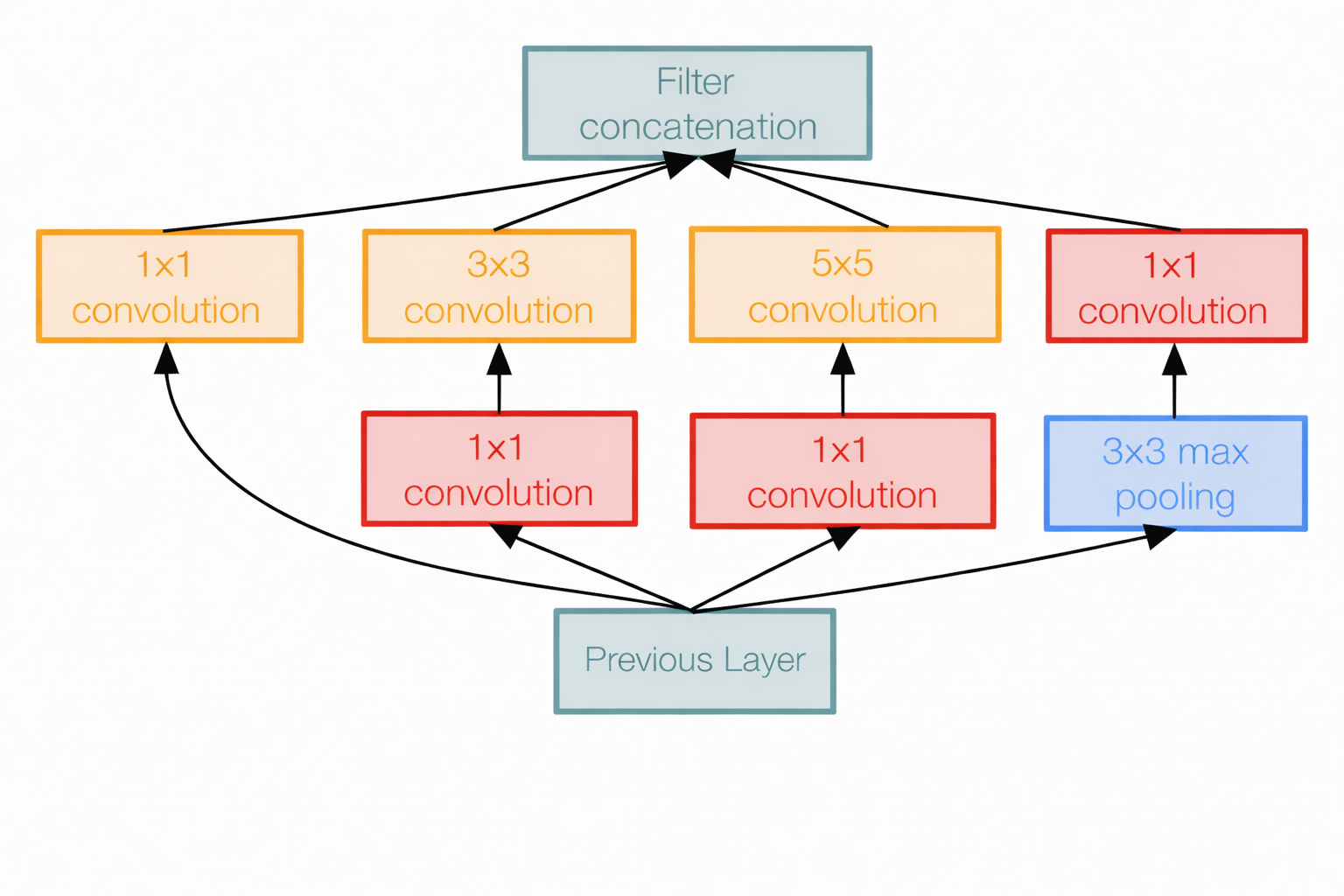
Inception Structure
Parallel branches:
- 1×1
- 3×3
- 5×5
- 3×3 MaxPool
Concatenate outputs.
2. Main Idea
- The main point of model found that a number of 3x3 kernel size makes too much huge parameters and lack of memory when having many layers.
| Model | Year | Depth | Parameters (approx.) | Key Characteristics |
|---|---|---|---|---|
| VGG-16 | 2014 | 16 layers | 138 million | Repeated 3×3 convolutions, very large fully connected layers |
| VGG-19 | 2014 | 19 layers | 144 million | Deeper version of VGG-16 |
| GoogLeNet (Inception v1) | 2014 | 22 layers | 6.8 million | Uses Inception modules with 1×1 convolutions for dimensionality reduction |
ResNet
1. Structure
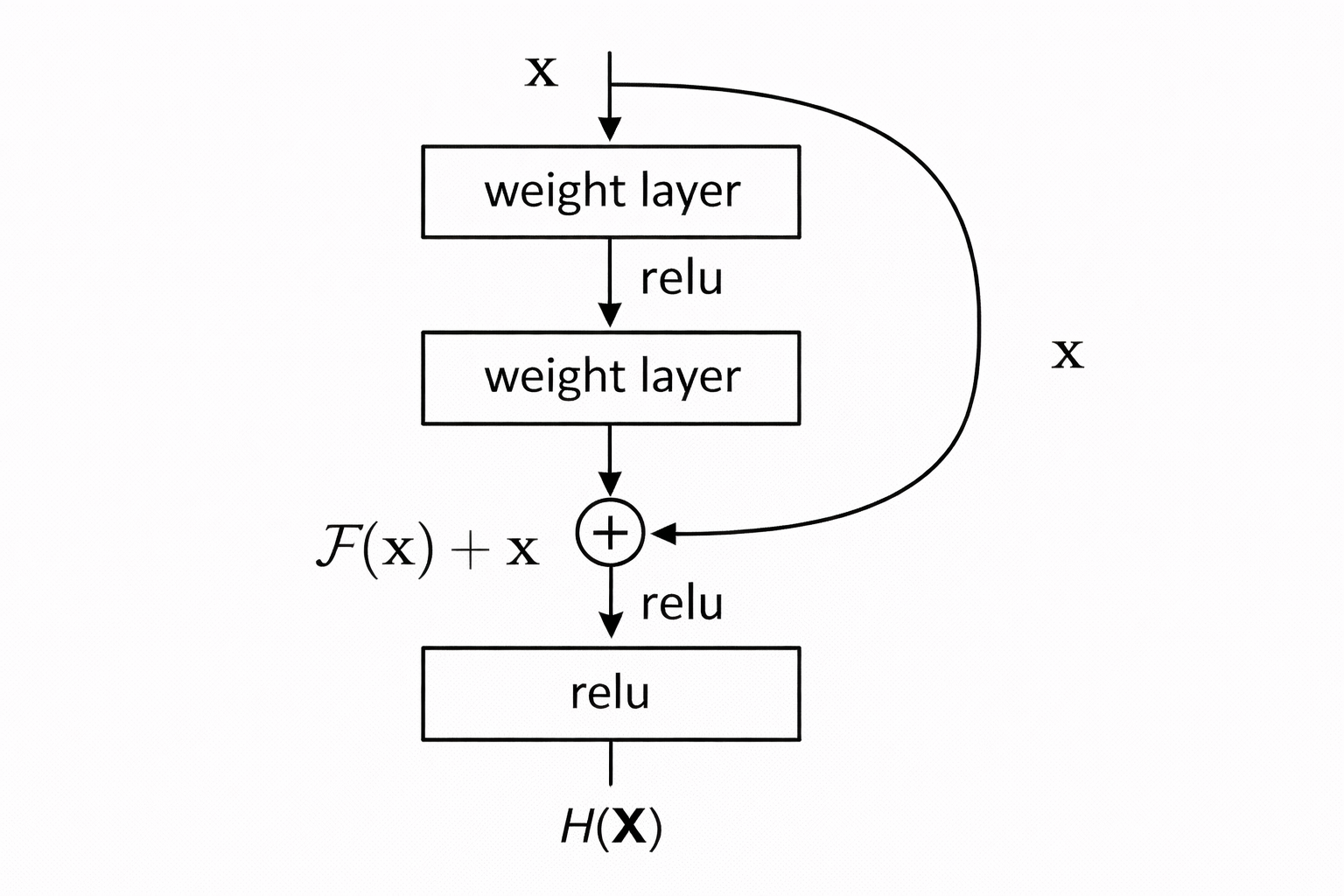
Instead of learning H(x), learn residual:
\[H(x) = F(x) + x\]Residual block:
\[y = F(x) + x\]Where:
\[F(x) = W_2 \sigma(W_1 x)\]2. Main Idea
ResNet enables very deep networks by adding identity shortcut connections. If a layer cannot learn a useful transformation, it can simply learn a near-zero residual and behave like an identity mapping. This helps preserve information and allows gradients to flow more easily, mitigating the vanishing gradient problem. Now we can enable very deep networks (100+ layers)