03. Recurrent Neural Network
03. Recurrent Neural Network
Recurrent Neural Network
Prerequisites
1
1. Convolutional Neural Network <b>Convolutional Neural Network</b> is focus on spatial locality and positional invariance. It can <span style="color:#FFD5D5">NOT</span> reflect to sequential information. Because it have fixed filter size, but variable length is in real
What is Recurrent Neural Network(RNN)
1. What is Recurrent Neural Network(RNN)?
A Model that use learnable state parameters composed of sharing every step when we infer the information without fixed length.
Structure
\[Input \rightarrow RNN \rightarrow RNN \rightarrow RNN ... \rightarrow Softmax \rightarrow Output\]- Can have current state with RNN parameters
- it is cruial impact included with vanishing or exploding gradient.
2. Why use Recurrent Neural Network(RNN)?
1
Keep Memory
Many real-world problems are time-dependent like video, speech and so on. For solving this issue, we should capture temporal dependency with something having memory. In this model, parameter sharing over time can be memory on step by step.
3. How use Recurrent Neural Network(RNN)?
1
Hidden State
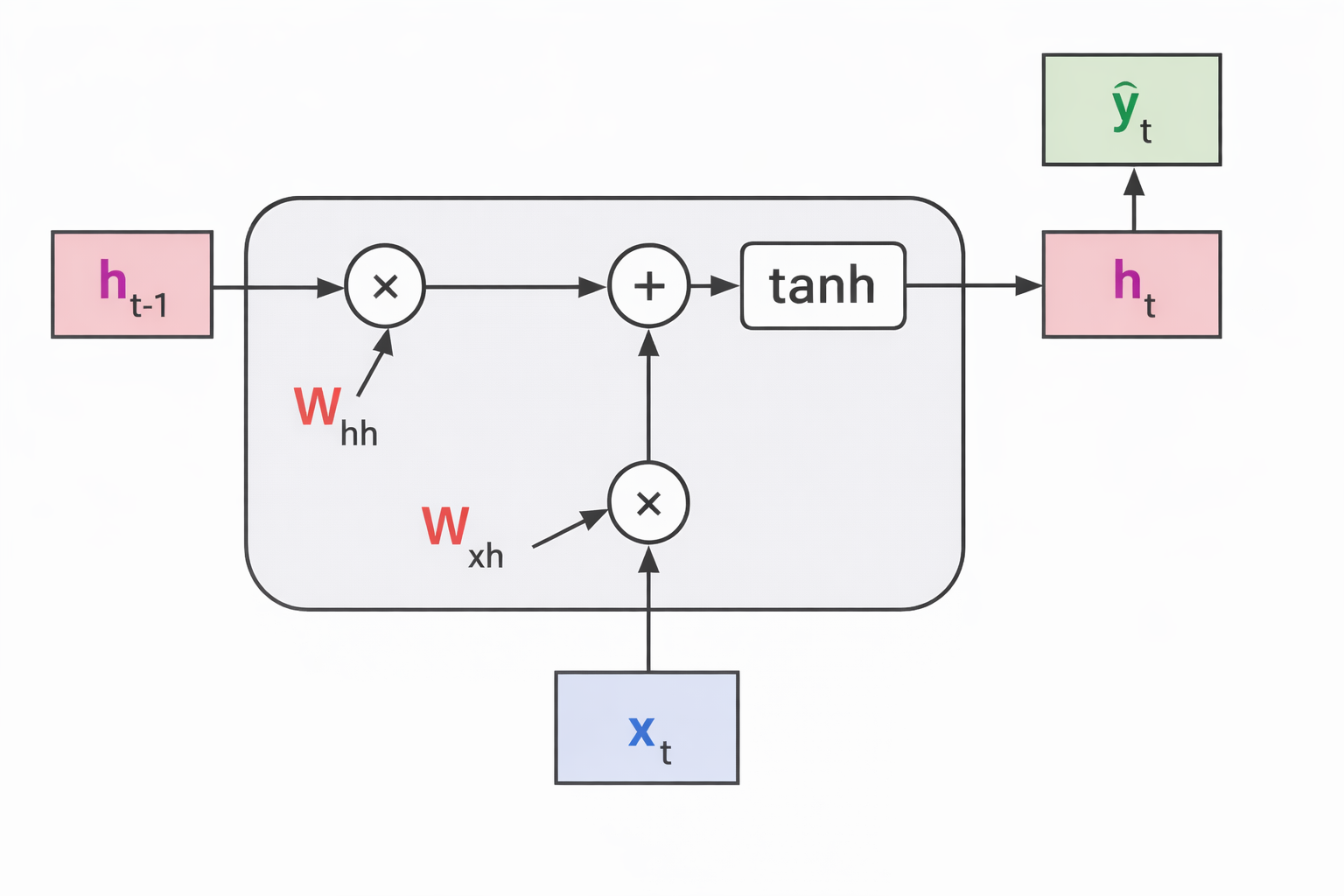
Where:
- $W_{hh}$ : hidden-to-hidden weights
- $W_{xh}$ : input-to-hidden weights
- $b_h$ : bias
Output Layer: \(\hat{y} = \sigma(W_{hy} h_T + b_y)\)
Binary cross-entropy:
\[\mathcal{L} = - \left[ y \log \hat{y} + (1-y) \log (1-\hat{y}) \right]\]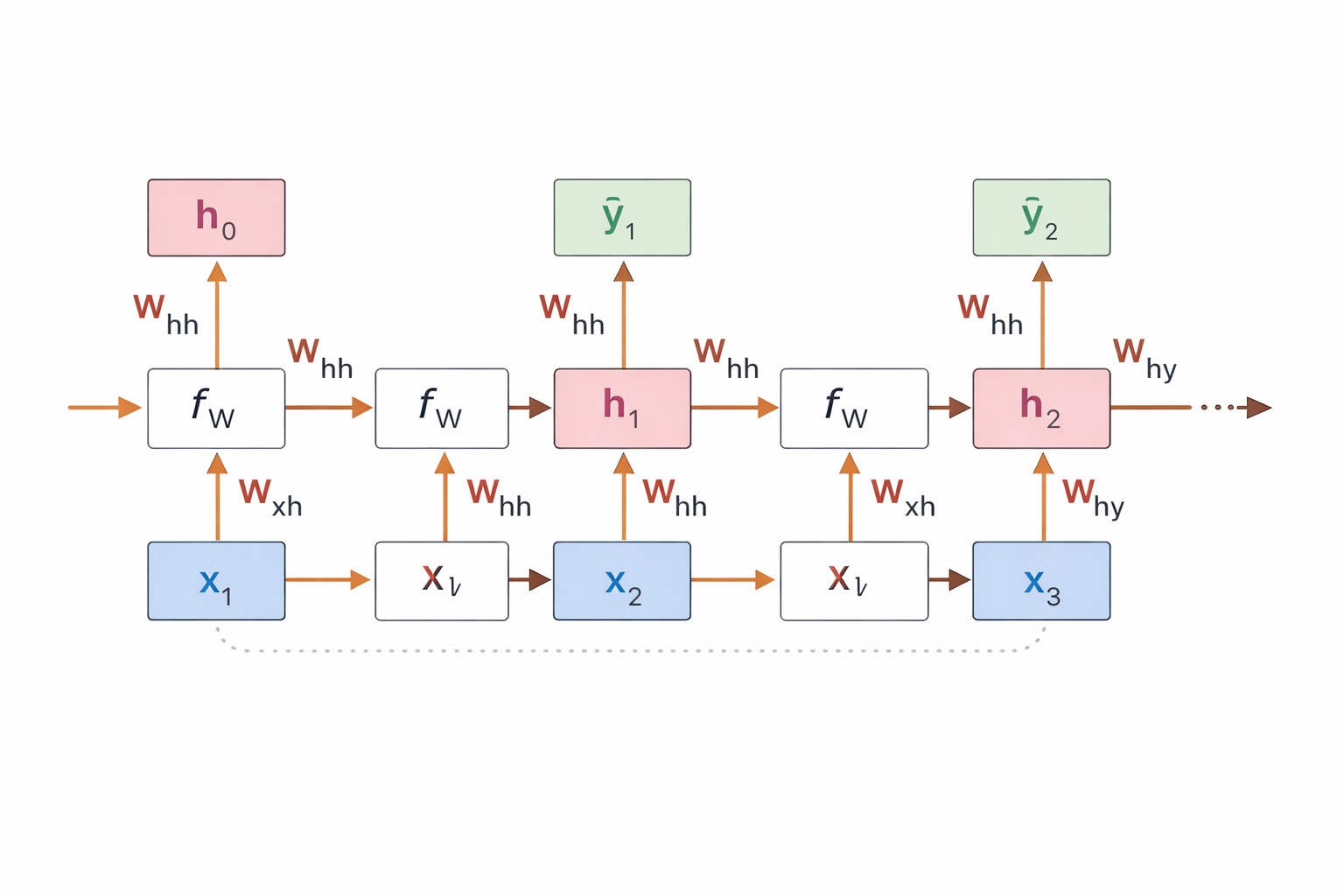
4. What is CRITICAL PROBLEM of Recurrent Neural Network(RNN)?
1
2
1. Vanishing Gradient
2. Exploding Gradient
Backpropagation through time produces:
\[\frac{\partial L}{\partial h_k} = \frac{\partial L}{\partial h_t} \prod_{i=k+1}^{t} \frac{\partial h_i}{\partial h_{i-1}}\]And
\[\frac{\partial h_t}{\partial h_{t-1}} = \tanh'(W_{hh} h_{t-1} + W_{xh} x_t) W_{hh}\]🎯 Meaning
- If largest singular value of $W_{hh}$ > 1 → exploding gradient
- If < 1 → vanishing gradient
- $\tanh’$ ≤ 1 almost always → shrinking effect
This post is licensed under CC BY 4.0 by the author.