05. Gated Recurrent Units (GRU)
05. Gated Recurrent Units (GRU)
Gated Recurrent Units (GRU)
Prerequisites
1
2
1. Recurrent Neural Network
2. LSTM <b>Recurrent Neural Network</b> have a problem when training owing to update gradient without insecure like <span style="color:#FFD5D5">vanishing or exploding gradient</span>. This leads to exponential growth or decay of gradients. LSTM is good solution of gradient issue. but it is not also completely solving the problem.
What is Gated Recurrent Units (GRU)
1. What is Gated Recurrent Units (GRU)?
A Model that is similar structure with RNN parameters</span>. But it is more preventing gradient update issue while long term sequence.
Structure
\[Input \rightarrow GRU \rightarrow GRU \rightarrow GRU ... \rightarrow Softmax \rightarrow Output\]- Can have more secure model with convex combination
- it is also having vanishing or exploding gradient problem if sequence is too long.
2. Why use Gated Recurrent Units (GRU)?
1
2
1. Keep Memory
2. convex combination
Simpler alternative to LSTM. No separate cell state.
3. How use Gated Recurrent Units (GRU)?
1
Hidden State
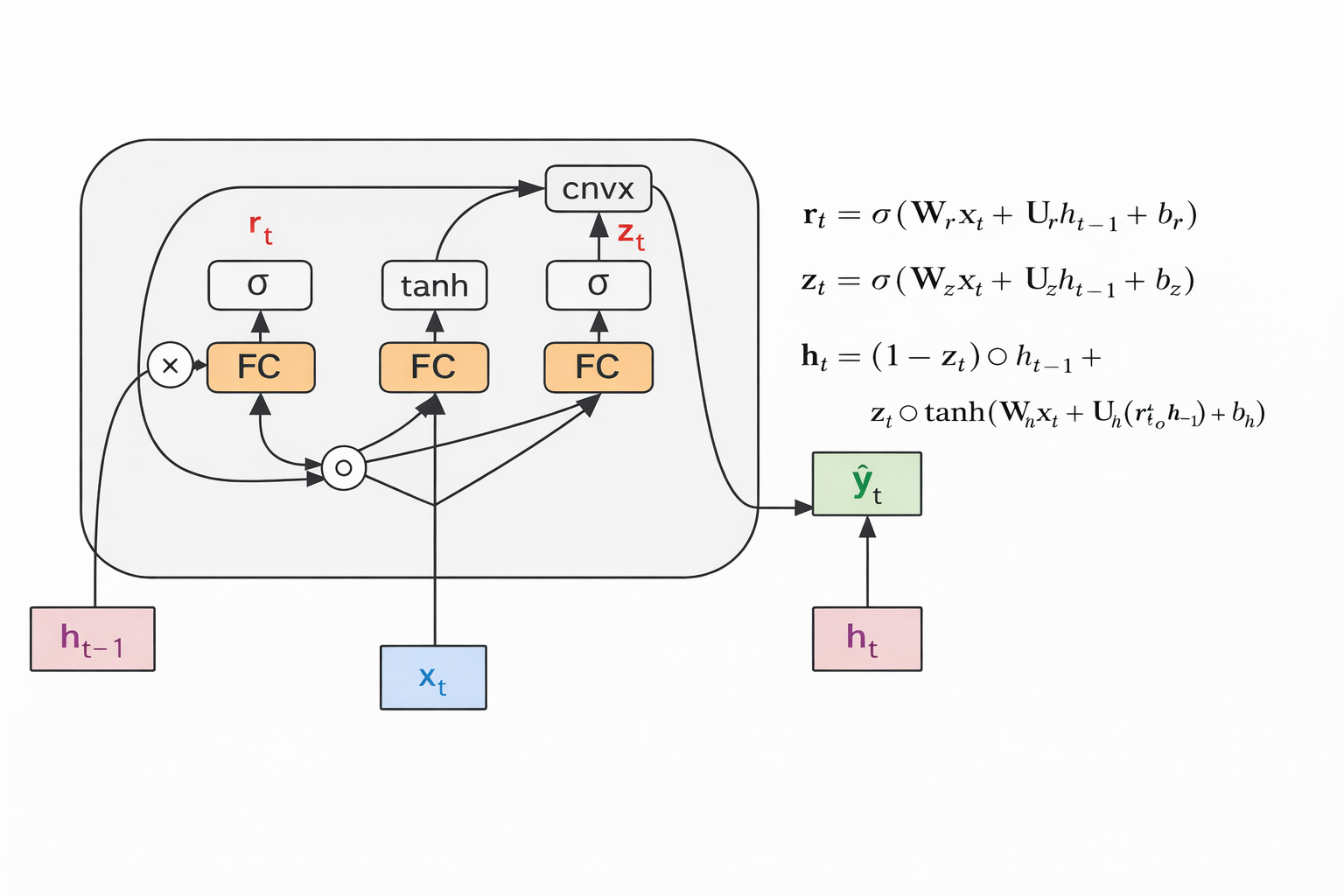
- $ Reset Gate: r_t = \sigma(W_r x_t + U_r h_{t-1} + b_r) $
- $ Update Gate: z_t = \sigma(W_z x_t + U_z h_{t-1} + b_z) $
- $ Candidate Hidden: \tilde{h}t = \tanh(W_h x_t + U_h (r_t \odot h{t-1}) + b_h)$
- $ Final Hidden: h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t $
4. What is FEW PROBLEM of Gated Recurrent Units (GRU)?
1
2
1. Vanishing Gradient
2. Exploding Gradient
It is also remain the gradient problem. but it is more better than Vanilla RNN
This post is licensed under CC BY 4.0 by the author.