Hands-on 05. Random Forest
Hands-on 05. Random Forest
Random Forest
Prerequisites
1
Random Forest
1. How to implement the real
Random Forest is ensembling model with various random decision tree. Each trees has different features from being choosed randomly and structure. So when it comes to inference with each trees, combined the each decision and build the result like average, majority vote
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, r2_score
RANDOM_STATE = 42
def train_random_forest(df):
# Drop rows involved NA
df = df.copy()
rf_features = [
"bedrooms",
"bathrooms",
"garage",
"land_area",
"floor_area",
"latitude",
"longitude",
"cbd_dist",
"nearest_stn_dist",
"nearest_sch_dist",
]
available_features = [c for c in rf_features if c in df.columns]
model_df = df.dropna(subset=available_features + ["price"]).copy()
if len(model_df) < 100:
df["predicted_price"] = np.nan
df["prediction_gap"] = np.nan
df["prediction_gap_pct"] = np.nan
return df, {"mae": None, "r2": None, "features": []}
X = model_df[available_features]
y = model_df["price"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=RANDOM_STATE
)
# set model
model = RandomForestRegressor(
n_estimators=120,
max_depth=14,
min_samples_leaf=4,
random_state=RANDOM_STATE,
n_jobs=-1,
)
# train
model.fit(X_train, y_train)
# inference
y_pred = model.predict(X_test)
all_pred = model.predict(X)
# result
model_df["predicted_price"] = all_pred
model_df["prediction_gap"] = model_df["predicted_price"] - model_df["price"]
model_df["prediction_gap_pct"] = model_df["prediction_gap"] / model_df["predicted_price"]
df["predicted_price"] = np.nan
df["prediction_gap"] = np.nan
df["prediction_gap_pct"] = np.nan
df.loc[model_df.index, ["predicted_price", "prediction_gap", "prediction_gap_pct"]] = model_df[["predicted_price", "prediction_gap", "prediction_gap_pct"]]
importance = sorted(
zip(available_features, model.feature_importances_),
key=lambda x: x[1], reverse=True,
)
metrics = {
"mae": float(mean_absolute_error(y_test, y_pred)),
"r2": float(r2_score(y_test, y_pred)),
"features": importance[:8],
}
return df, metrics
df = pd.read_csv("data.csv")
df, metrics = train_random_forest(df)
1-1. Data
- Select features
- Split train and test data
1-2. Random Forest
Set model parameters
- Number of estimators (tree count)
- Maximum depth
- Minimum samples per leaf
- Number of features to consider at each split
Process as follows:
Create a Decision Tree
- Generate a bootstrap sample (random sampling with replacement)
At each node:
- Randomly select a subset of features
- For each selected feature, test all possible split thresholds
- Choose the split that minimizes error (e.g., MSE)
- Split the data based on the best condition
- Repeat recursively until stopping criteria are met (e.g., max depth, minimum samples)
Repeat tree creation
- Build multiple trees independently using different random samples
- Continue until the total number of estimators is reached
Make predictions
- Pass input data through all trees
Aggregate results:
- Regression → average
- Classification → majority vote
1.3 In real
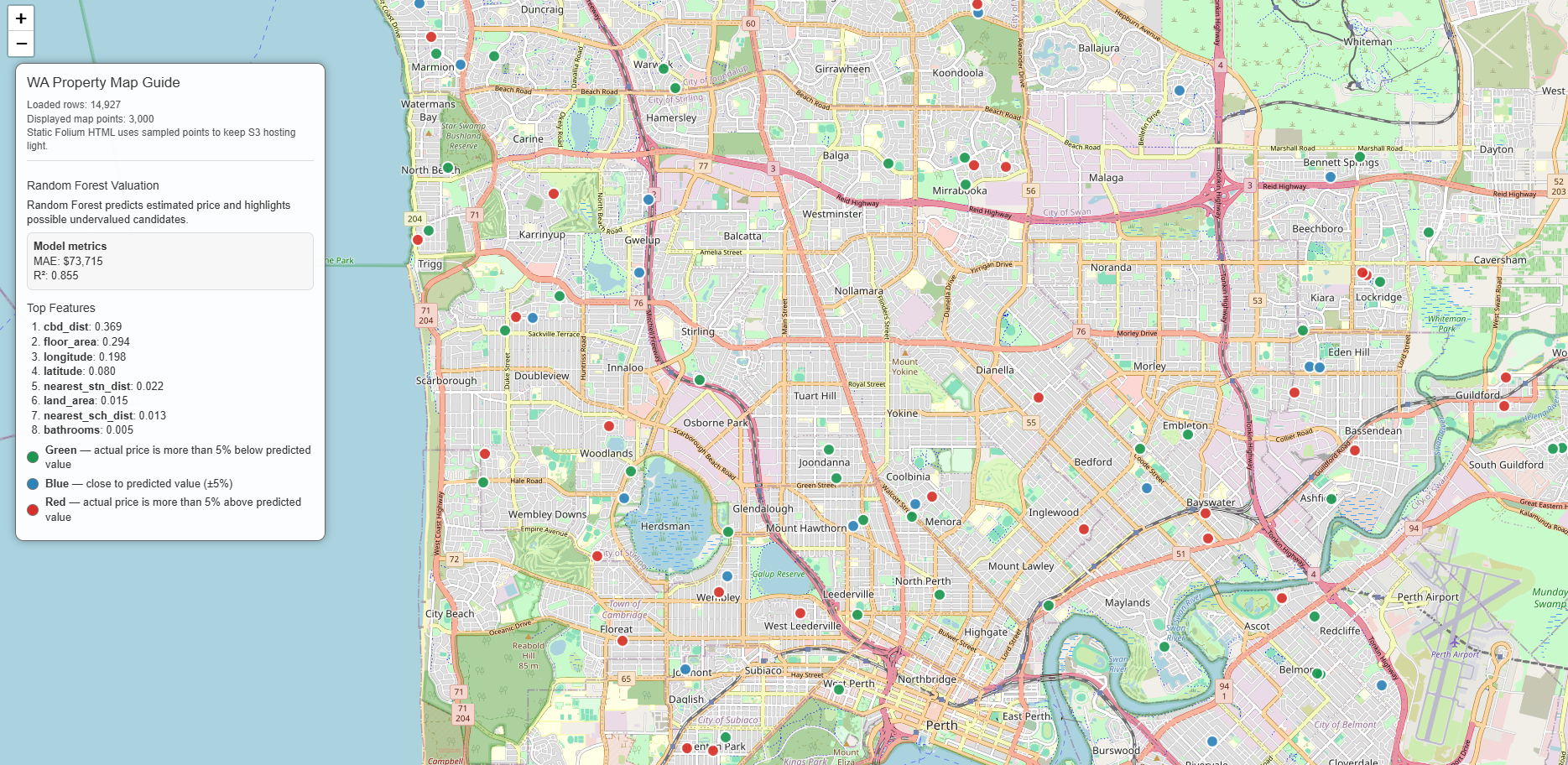
2. How to work Random Forest
1
2
3
4
5
Random Forest =
Data randomness +
Feature randomness +
Optimal split selection +
Aggregation (average / vote)
Random Forest is an ensemble learning method used to improve prediction accuracy by combining multiple decision trees. Instead of relying on a single tree, it builds many trees using randomness and aggregates their results.
Complexity Comparison:
1
2
Single Decision Tree: High variance (overfitting risk)
Random Forest: Reduced variance (stable prediction)
2-1. Build Process (Tree Construction)
Random Forest builds multiple decision trees using:
1
2
3
1. Bootstrap Sampling (random data)
2. Random Feature Selection
3. Best Split Selection (not random split)
Example Data
1
2
3
4
5
6
7
House : (bedrooms, area, cbd_dist) → price
A : (2, 300, 15) → 500k
B : (3, 500, 10) → 800k
C : (4, 700, 5) → 1200k
D : (3, 400, 12) → 700k
E : (5, 900, 3) → 1500k
> Tree 1
Step 1: Bootstrap Sampling
1
[A, B, C, D]
Step 2: Random Feature Selection
1
2
Selected features:
area, cbd_dist
Step 3: Try multiple split candidates
1
2
3
area < 400
area < 600
cbd_dist < 10
Step 4: Evaluate each split (MSE)
1
2
3
area < 400 → MSE = 120k
area < 600 → MSE = 80k ✅ best
cbd_dist < 10 → MSE = 150k
Step 5: Choose best split
1
if area < 600
> Tree 2
Step 1: Bootstrap Sampling
1
[B, C, D, E]
Step 2: Random Feature Selection
1
2
Selected features:
bedrooms, cbd_dist
Step 3: Split candidates
1
2
3
bedrooms < 4
cbd_dist < 8
cbd_dist < 15
Step 4: Evaluation
1
2
3
bedrooms < 4 → MSE = 90k
cbd_dist < 8 → MSE = 70k ✅ best
cbd_dist < 15 → MSE = 100k
Step 5: Best split
1
if cbd_dist < 8
> Tree 3
Step 1: Bootstrap Sampling
1
[A, C, E]
Step 2: Random Feature Selection
1
2
Selected features:
area, bedrooms
Step 3: Split candidates
1
2
area < 500
bedrooms < 4
Step 4: Evaluation
1
2
area < 500 → MSE = 60k ✅ best
bedrooms < 4 → MSE = 110k
Step 5: Best split
1
if area < 500
> Final Tree Concept
Each tree is:
1
2
3
- trained on different data
- uses different features
- finds different decision rules
2-2. Prediction
1
2
Predict price for:
(3 bedrooms, 450 area, cbd_dist = 10)
Step 1: Run all trees
1
2
3
Tree 1 → 1000k
Tree 2 → 750k
Tree 3 → 650k
Step 2: Aggregate results
For regression:
1
2
3
Final = Average
(1000 + 750 + 650) / 3 = 800k
For classification:
1
2
3
4
5
Tree1 → Premium
Tree2 → Mid
Tree3 → Mid
Final = Majority Vote → Mid
This post is licensed under CC BY 4.0 by the author.