Memory - Memory Latency
Memory - Memory Latency
🧠 Memory Latency Hierarchy — Why Caches Matter
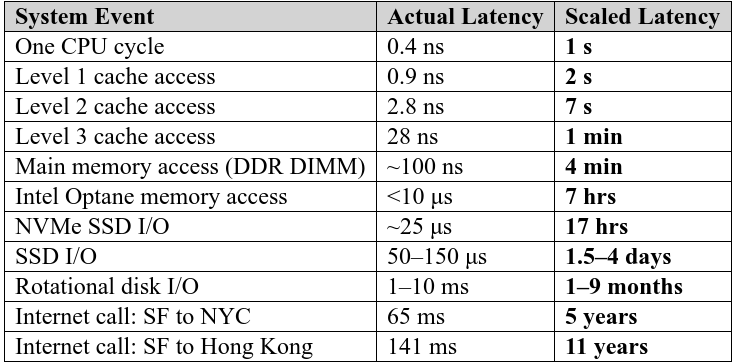
This table compares hardware access latency with a scaled real-world time analogy
to illustrate how dramatically access time increases across memory/storage layers.
1️⃣ Memory Access Latency Comparison
| System Event | Actual Latency | Scaled Human-Time Analogy |
|---|---|---|
| CPU Register / 1 CPU cycle | ~0.4 ns | 1 second |
| L1 Cache Access | ~0.9 ns | 2 seconds |
| L2 Cache Access | ~2.8 ns | 7 seconds |
| L3 Cache Access | ~28 ns | 1 minute |
| Main Memory (RAM) | ~100 ns | 4 minutes |
| Optane / Persistent Memory | ~10 µs | 7 hours |
| NVMe SSD I/O | ~25 µs | 17 hours |
| SSD I/O | ~50–150 µs | 1.5–4 days |
| HDD (Rotational Disk) | ~1–10 ms | 1–9 months |
| Internet (SF → NYC) | ~65 ms | 5 years |
| Internet (SF → Hong Kong) | ~141 ms | 11 years |
2️⃣ Key Insight — Latency Grows Explosively
Each step down the hierarchy is orders of magnitude slower:
- Register → Cache: ~2× slower
- Cache → RAM: ~100× slower
- RAM → SSD: ~1,000× slower
- SSD → HDD: ~10,000× slower
- Disk → Internet: Millions of times slower
This is why memory locality and caching dominate real-world performance.
3️⃣ Why Data Is Accessed in This Order
(L1 → L2 → L3 → RAM → Storage)
✅ Reason 1 — Speed vs Cost Tradeoff
| Layer | Speed | Cost | Capacity |
|---|---|---|---|
| Registers | Fastest | Very expensive | Tiny |
| L1 Cache | Very fast | Expensive | Small |
| L2 Cache | Fast | Expensive | Medium |
| L3 Cache | Slower | Cheaper | Larger |
| RAM | Much slower | Affordable | Large |
| Storage | Slowest | Cheapest | Huge |
We cannot build large memory entirely from ultra-fast storage — too expensive and power-hungry.
✅ Reason 2 — Locality of Reference
Programs tend to:
- Reuse recent data (temporal locality)
- Access nearby memory (spatial locality)
So CPU checks fast memory first, because it is likely already there.
✅ Reason 3 — Avoiding Massive Stall Time
If CPU accessed RAM every time:
- Pipeline stalls
- CPU idle time skyrockets
- Performance collapses
Caches hide RAM latency so the CPU stays busy.
✅ Reason 4 — Hierarchical Filtering Model
Think of memory like a search chain:
This post is licensed under CC BY 4.0 by the author.